Some automations start as a script and collapse as soon as volume grows. SwimUpvote was designed the other way around: as an operational platform for coordinating campaigns, conversation discovery, account warmup, scheduled tasks and distributed execution.
The goal was not to build "a Reddit bot". The goal was to build a command center where an operator can see what is happening, which account is running which job, whether a workflow belongs to browser or mobile execution, what is waiting in the queue and what result came back to the backend.
The problem it solves
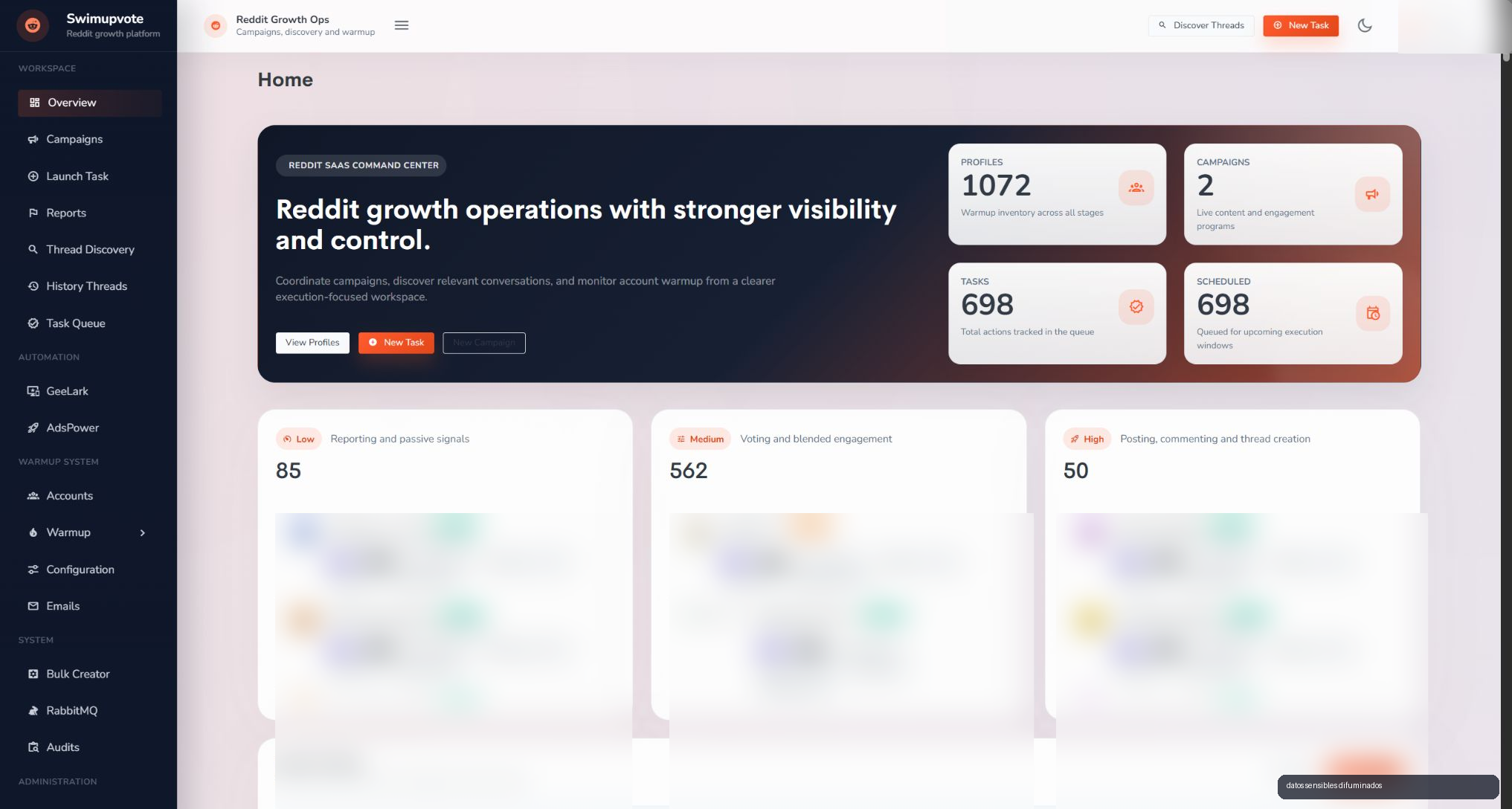
When you work with many Reddit accounts, the hard part is no longer clicking a button or sending an action. The hard part becomes coordination: which account is ready, which one needs warmup, which profile has an AdsPower environment, which one has a GeeLark environment, which task is scheduled, what failed and where the evidence lives.
SwimUpvote centralizes that operation. The panel covers profiles, campaigns, thread discovery, task queues, reports, logs, warmup, proxies, emails, RabbitMQ and administration tools. It is a control layer so the system does not depend on memory, spreadsheets or scattered scripts.
Real scale does not come from one worker
Managing 5000 Reddit accounts smoothly does not mean running 5000 things at the same time. It means having the architecture for 5000 identities to exist, be segmented, warmed up, scheduled, paused, audited and recovered without turning the operation into chaos.
The technical base of SwimUpvote separates the pieces that usually get mixed together too early:
- backend and panel for profiles, campaigns, tasks and audit trails
- RabbitMQ to decouple job creation from execution
- AdsPower consumers for browser-based automation
- GeeLark scheduler with Appium and ADB for mobile workflows
- account or profile locks to prevent conflicting parallel execution
- START, HEARTBEAT, END, ERROR and internal log reporting
- retries and backoff for recoverable failures
That design lets the system grow through real capacity: more profiles, more slots, more workers, more queues and better scheduling rules. It is not magic. It is the separation of control, execution and observability.
Two execution engines: browser and mobile
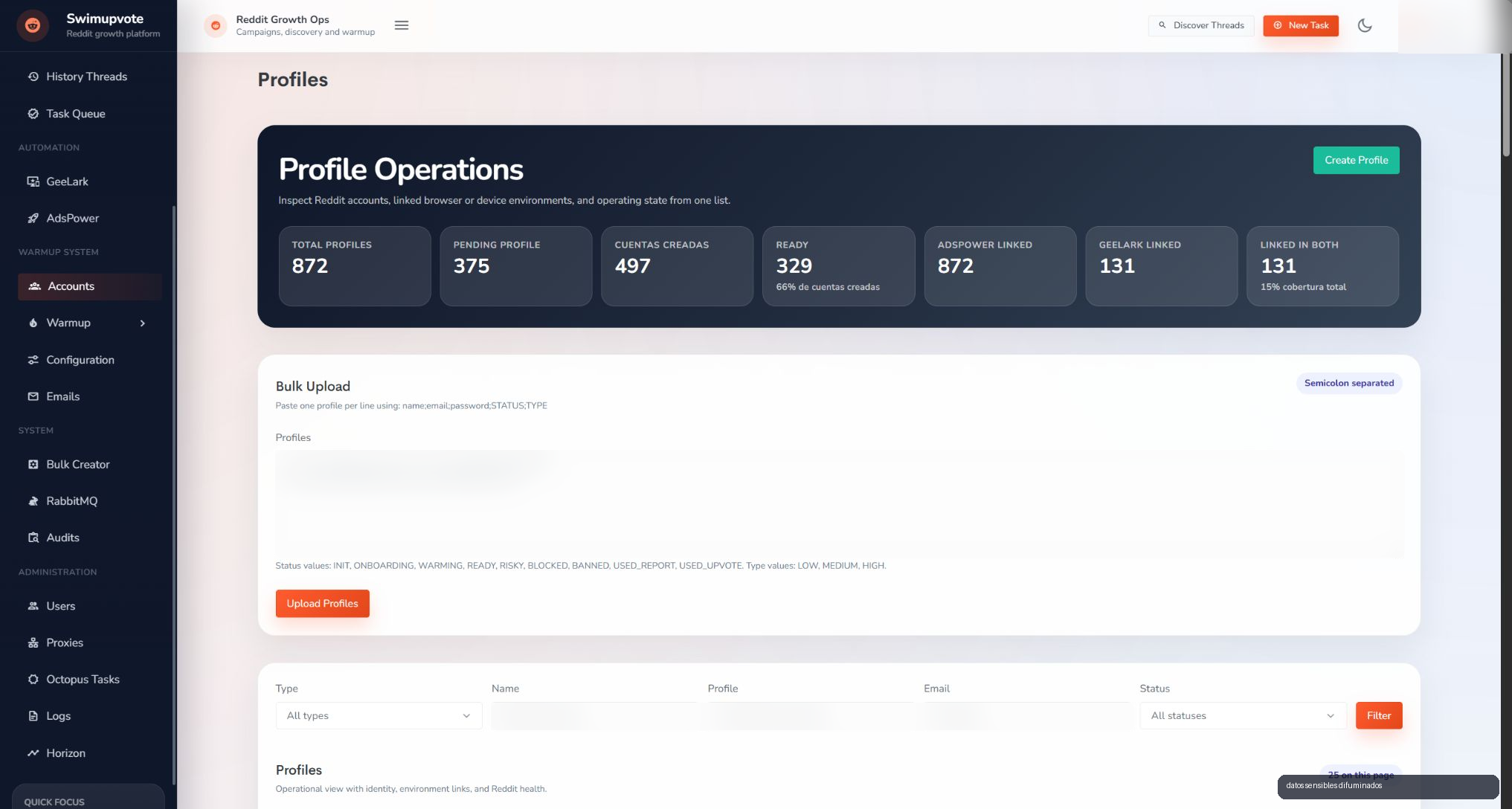
One part of the project works with browser profiles through AdsPower. That side handles flows such as account creation, email verification, 2FA enablement, warmup days, account info, comments, posts, upvotes, downvotes and reports.
The other side uses GeeLark, Appium and ADB to operate through mobile environments. The scheduler reserves slots, starts devices, connects ADB, opens an Appium session, runs the action and reports the result. Each slot works in isolation, and each account is locked while a job is active.
The benefit of this split is that the system does not force every workflow into one model. Some tasks fit better in a browser. Others make more sense on mobile. SwimUpvote can orchestrate both while keeping one operational view.
The queue is the operational core
The task queue is where you can tell whether a system is serious. Launching jobs is not enough: you need to know when they entered, what type they are, which account they use, which campaign created them, what state they are in, whether there is a screenshot, when they are scheduled and what action the operator can take.
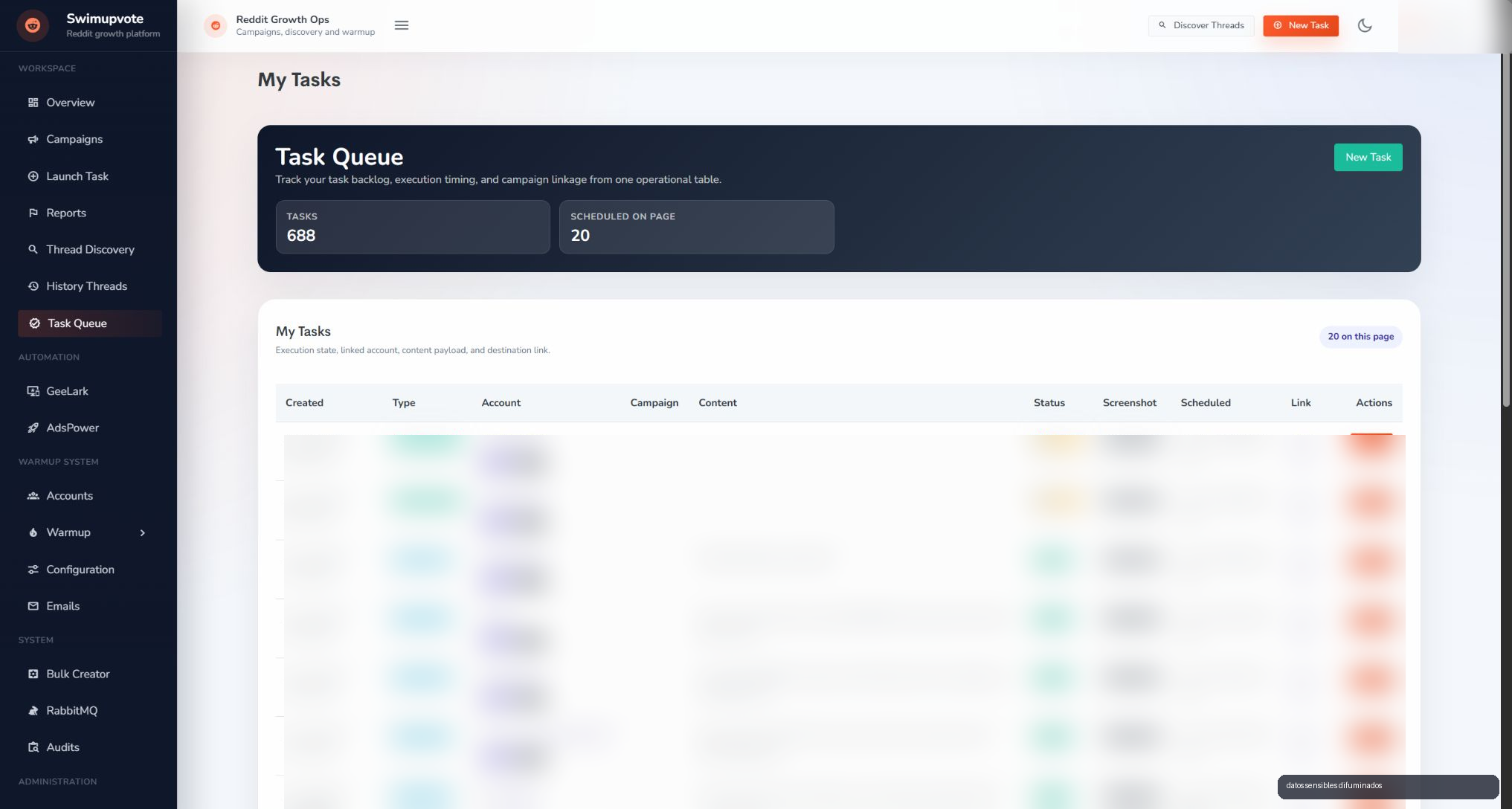
Underneath, RabbitMQ decouples the panel from the workers. If there are more jobs than available capacity, they wait. If a profile is already busy, parallel execution for that identity is blocked. If an error is recoverable, it goes into retry with backoff. If it is not, the system marks it and reports it.
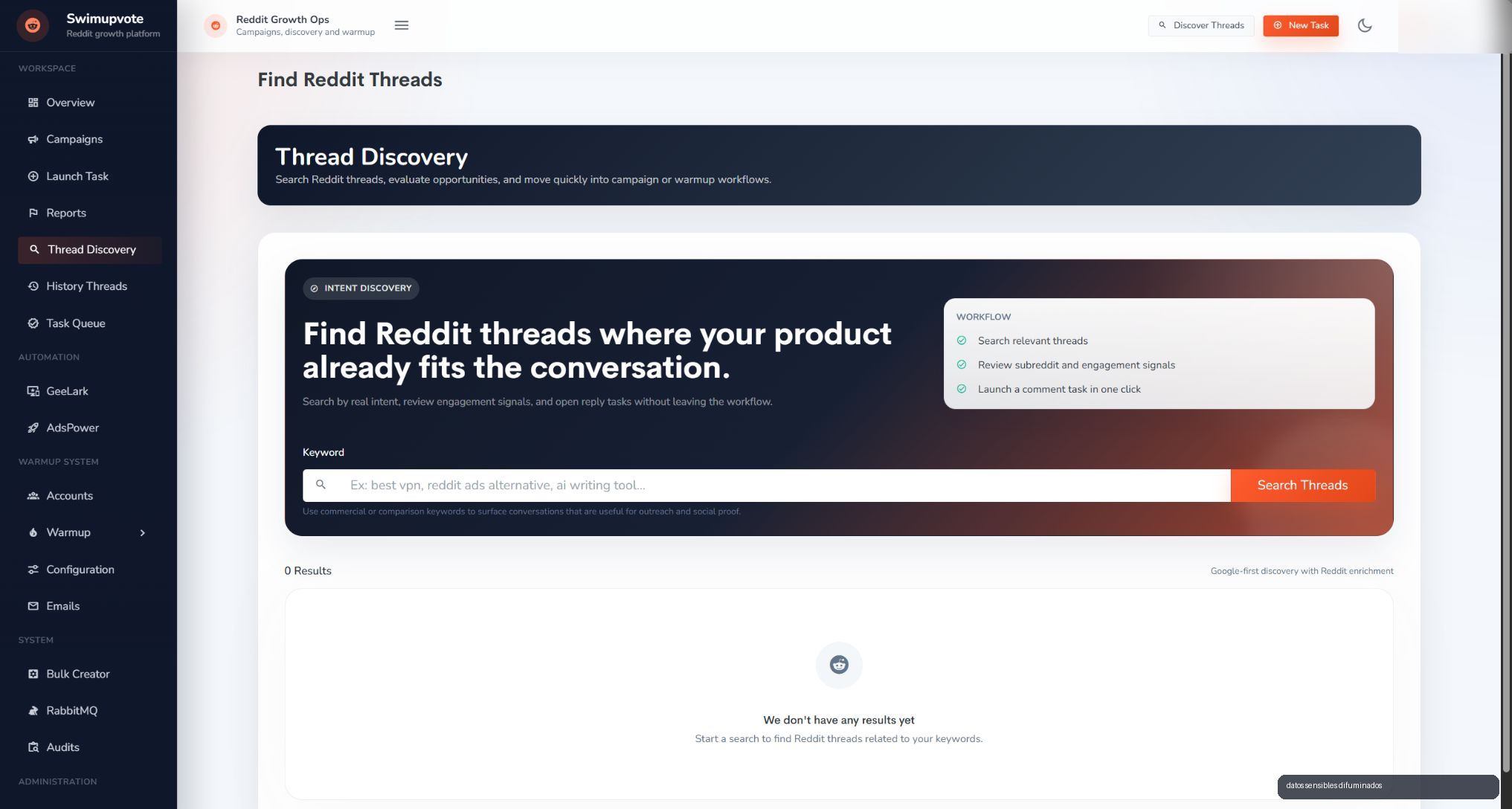
Discovery and campaigns without leaving the flow
SwimUpvote also includes a conversation discovery layer. The operator can search relevant threads, review signals and turn opportunities into tasks without leaving the workspace. That matters because it keeps the team from jumping between search tools, sheets and panels.
Why it can reach 5000 accounts
The big number is not carried by one function. It is carried by system discipline:
- centralized inventory of accounts and states
- clear separation between pending, created, ready and environment-linked profiles
- explicit mapping between account, browser environment and mobile environment
- workers that share no more state than necessary
- queues that absorb spikes without taking down the panel
- locks so one account does not receive incompatible jobs at the same time
- logs and callbacks to reconstruct what happened
- horizontal capacity through additional slots or workers where needed
With that foundation, 5000 accounts are not 5000 manual exceptions. They are 5000 records inside a measurable operation. That is the important jump.
What I am not showing in detail
Some parts should not be published precisely: real payloads, selectors, secrets, usernames, emails, task URLs, internal scoring rules or infrastructure configuration. The screenshots in this post are blurred for that reason.
The technical value worth showing is the architecture: separating panel, queue, workers, environments, locks, retries and reporting. That is the part that turns fragile automation into a maintainable platform.
Conclusion
SwimUpvote is an example of how I like to build automation systems: not as a collection of scripts, but as an operation with control, traceability and room to grow.
When the goal is to manage hundreds or thousands of accounts, the question is not only "can it execute the action?". The better question is: if something fails, do we know which account, which worker, which environment, which queue, which state and which decision caused it?
If the answer is yes, you no longer have only automation. You have operational infrastructure. That is where projects like SwimUpvote start to make real sense.