Hay automatizaciones que nacen como un script y mueren cuando el volumen sube. SwimUpvote fue al reves: desde el principio se penso como una plataforma operativa para coordinar campanas, descubrimiento de conversaciones, warmup de cuentas, tareas programadas y ejecucion distribuida.
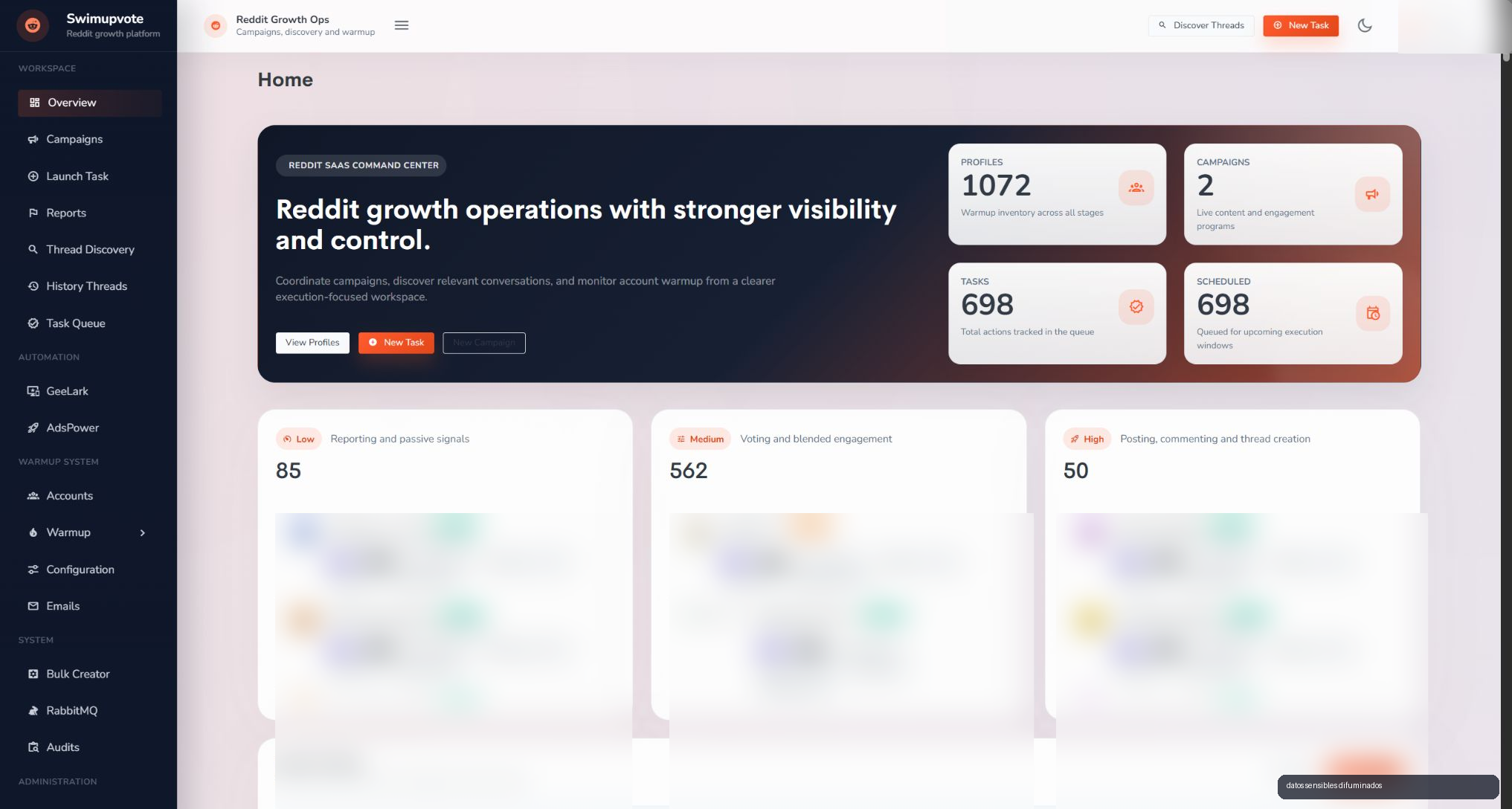
La idea no era tener "un bot de Reddit". La idea era construir un command center donde se pudiera ver que esta pasando, que cuenta ejecuta que trabajo, que flujo pertenece a navegador o movil, que tareas estan en cola y que resultado vuelve al backend.
Que problema resuelve
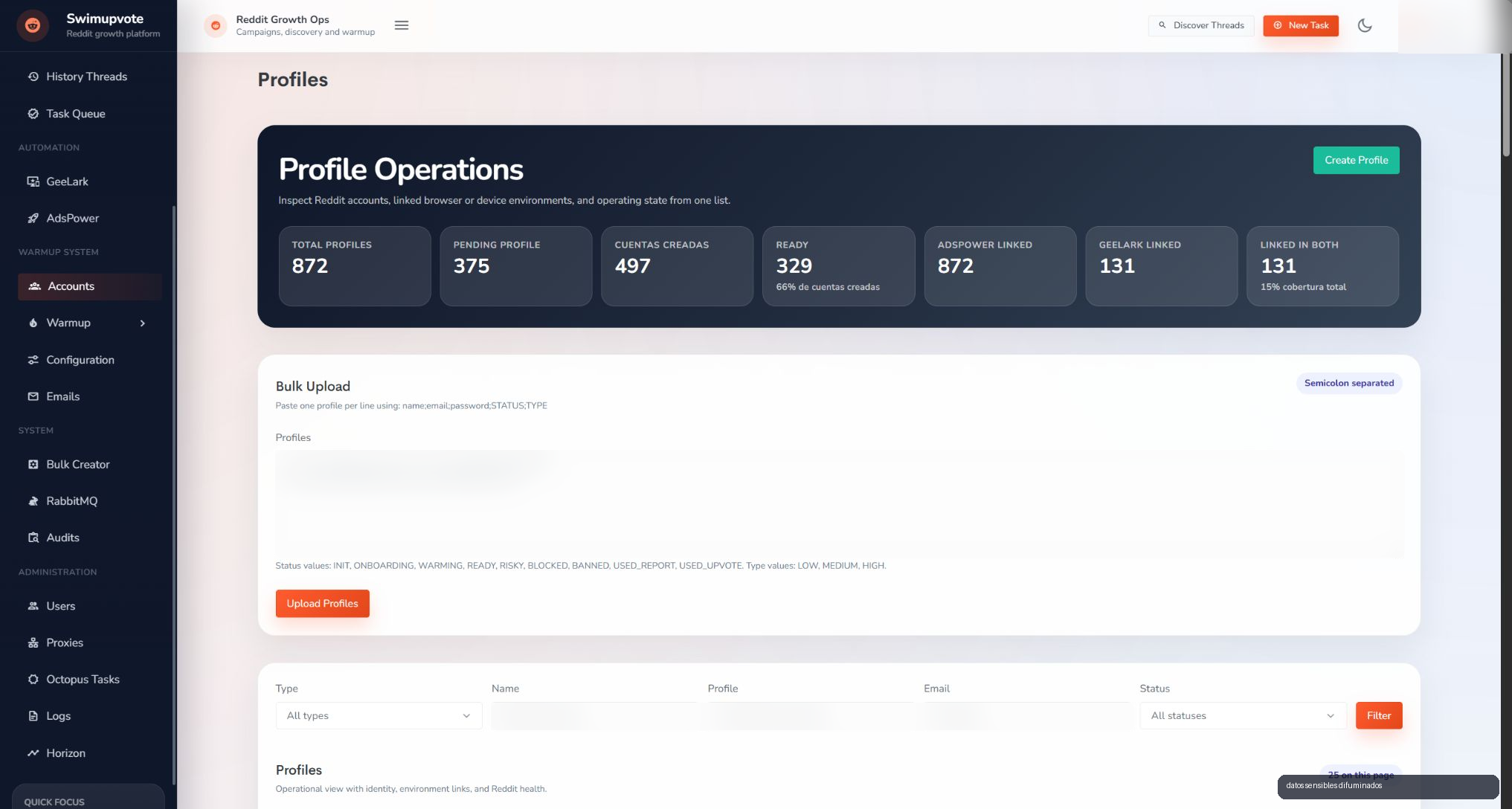
Cuando trabajas con muchas cuentas Reddit, el problema deja de ser "hacer click" o "mandar una accion". El problema pasa a ser coordinacion: que cuenta esta lista, que cuenta necesita warmup, que perfil tiene entorno AdsPower, que perfil tiene entorno GeeLark, que tarea esta programada, cual fallo y donde quedo la evidencia.
SwimUpvote centraliza esa operacion. El panel permite trabajar con perfiles, campanas, discovery de threads, task queue, reports, logs, warmup, proxies, emails, RabbitMQ y herramientas de administracion. Es una capa de mando para que el sistema no dependa de memoria, hojas de calculo o scripts sueltos.
La escala real no sale de un solo worker
Gestionar 5000 cuentas de Reddit sin problemas no significa ejecutar 5000 cosas a la vez. Significa tener arquitectura para que 5000 identidades puedan existir, segmentarse, calentarse, programarse, pausarse, auditarse y recuperarse sin convertir la operacion en caos.
La base tecnica de SwimUpvote separa las piezas que suelen mezclarse mal:
- backend y panel para perfiles, campanas, tareas y auditoria
- RabbitMQ para desacoplar la creacion de trabajos de la ejecucion
- consumidores AdsPower para automatizacion de navegador
- scheduler GeeLark con Appium y ADB para flujos moviles
- locks por cuenta o perfil para evitar dobles ejecuciones simultaneas
- reporting de estados START, HEARTBEAT, END, ERROR y logs internos
- reintentos y backoff para errores recuperables
Ese diseno permite crecer por capacidad real: mas perfiles, mas slots, mas workers, mas colas y mejores reglas de scheduling. No es magia. Es separar control, ejecucion y observabilidad.
Dos motores de ejecucion: navegador y movil
Una parte del proyecto trabaja con perfiles de navegador mediante AdsPower. Ahi viven flujos como creacion de cuenta, verificacion de email, activacion de 2FA, warmup por dias, informacion de cuenta, comentarios, posts, upvotes, downvotes y reports.
La otra parte usa GeeLark, Appium y ADB para operar desde entornos moviles. El scheduler reserva slots, arranca dispositivos, conecta ADB, abre una sesion Appium, ejecuta la accion y reporta el resultado. Cada slot trabaja de forma aislada y cada cuenta se bloquea mientras tiene un job activo.
La ventaja de esta division es que no fuerzas todo a un unico modelo. Hay tareas que encajan mejor en navegador y otras que tienen mas sentido en movil. SwimUpvote puede orquestar ambas sin que el panel pierda una vista unica de la operacion.
La cola es el corazon operativo
La task queue es donde se nota si el sistema es serio. No basta con lanzar trabajos: hay que saber cuando entraron, que tipo son, que cuenta usan, que campana los origino, que estado tienen, si hay screenshot, cuando estan programados y que accion permite el operador.
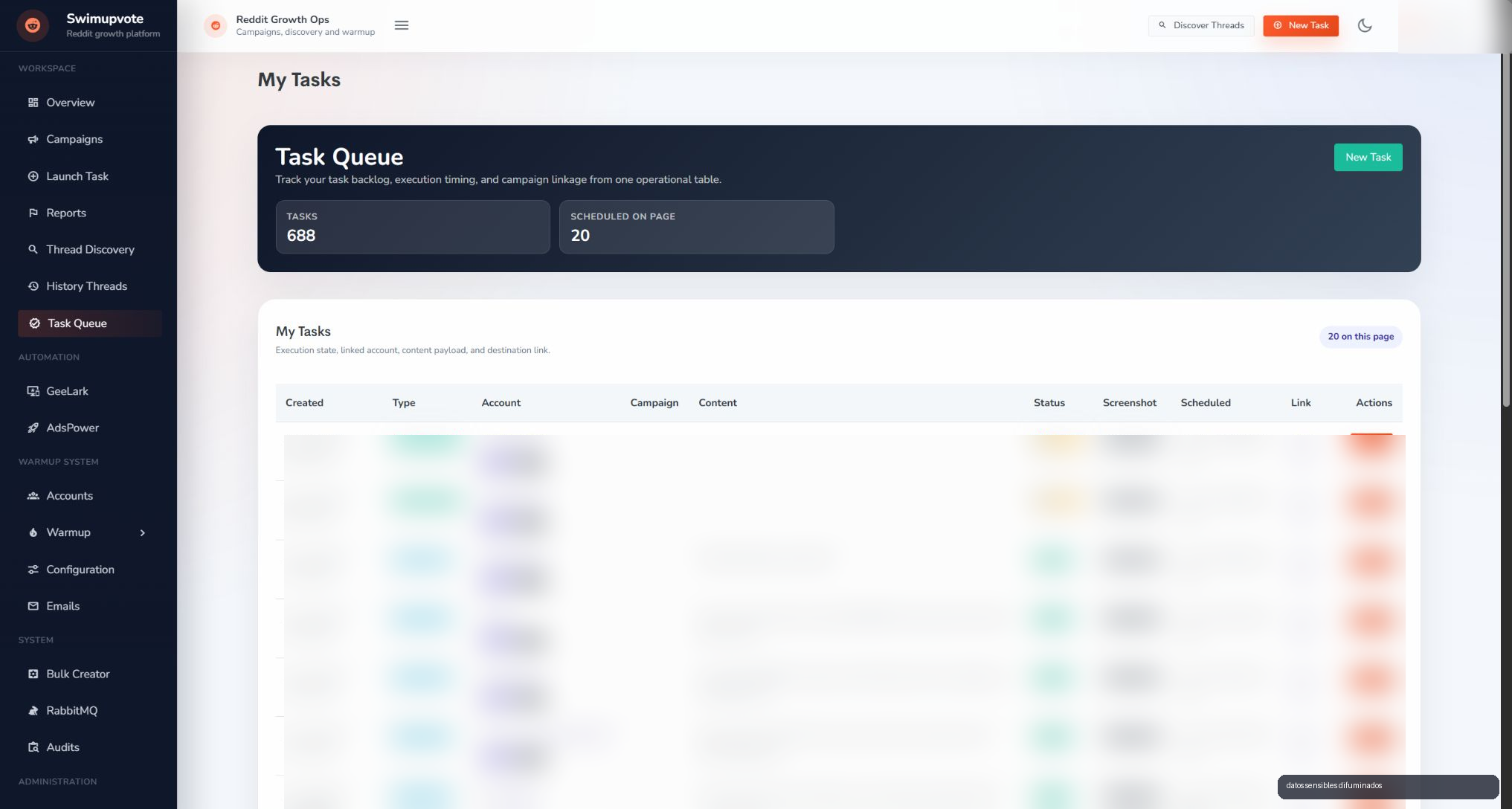
Por debajo, RabbitMQ desacopla el panel de los workers. Si hay mas trabajos que capacidad disponible, esperan. Si un perfil ya esta ocupado, se bloquea la ejecucion paralela para esa identidad. Si un error es recuperable, entra en retry con backoff. Si no lo es, se marca y se reporta.
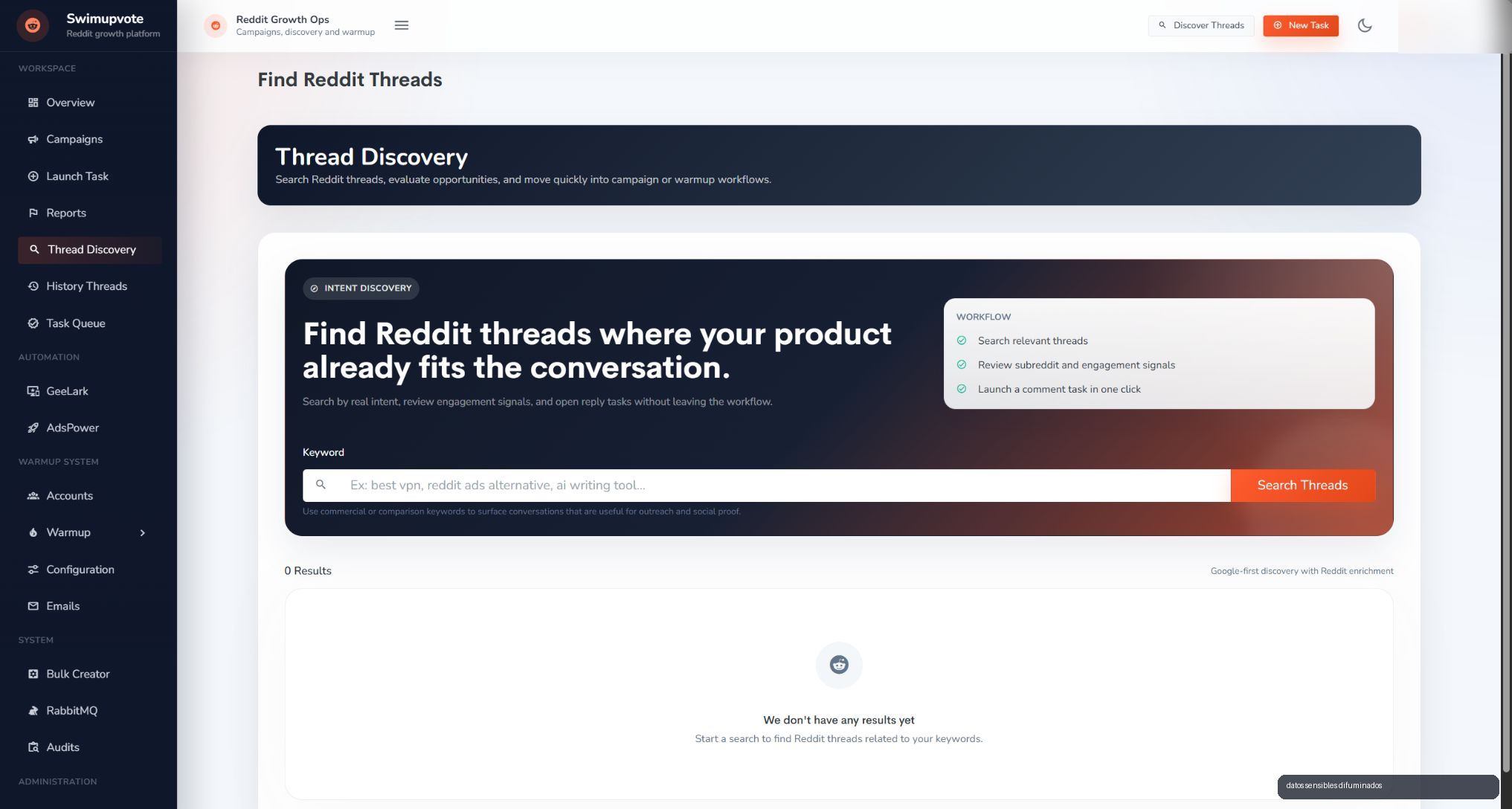
Discovery y campanas sin salir del flujo
SwimUpvote tambien incluye una capa de descubrimiento de conversaciones. El operador puede buscar threads relevantes, revisar senales y convertir oportunidades en tareas sin salir del workspace. Esa parte es importante porque evita que el equipo viva saltando entre buscadores, hojas y paneles.
Por que puede llegar a 5000 cuentas
El numero grande no lo aguanta una funcion concreta. Lo aguanta la disciplina del sistema:
- inventario centralizado de cuentas y estados
- separacion entre perfiles pendientes, creados, ready y vinculados a entornos
- relacion clara entre cuenta, entorno de navegador o entorno movil
- workers que no comparten mas estado del necesario
- colas que absorben picos sin tumbar el panel
- locks para que una misma cuenta no reciba dos jobs incompatibles
- logs y callbacks para reconstruir que paso
- capacidad horizontal: anadir slots o workers donde haga falta
Con esa base, 5000 cuentas no son 5000 excepciones manuales. Son 5000 registros dentro de una operacion medible. Ese es el salto importante.
Lo que no enseno en detalle
Hay partes que no conviene publicar con precision: payloads reales, selectores, secretos, usernames, emails, URLs de tareas, reglas internas de scoring o configuraciones de infraestructura. Las capturas de este post estan difuminadas justo por eso.
El valor tecnico que si se puede contar es la arquitectura: separar panel, cola, workers, entornos, locks, retries y reporting. Es la parte que convierte una automatizacion fragil en una plataforma mantenible.
Conclusion
SwimUpvote es un ejemplo de como me gusta construir sistemas de automatizacion: no como una coleccion de scripts, sino como una operacion con control, trazabilidad y capacidad de crecer.
Cuando el objetivo es manejar cientos o miles de cuentas, la pregunta no es solo "puede ejecutar la accion?". La pregunta buena es: si algo falla, sabemos que cuenta, que worker, que entorno, que cola, que estado y que decision lo provocaron?
Si la respuesta es si, entonces ya no tienes solo automatizacion. Tienes infraestructura operativa. Y ahi es donde proyectos como SwimUpvote empiezan a tener sentido de verdad.